比特币原理第一讲——区块链基本原型
简介
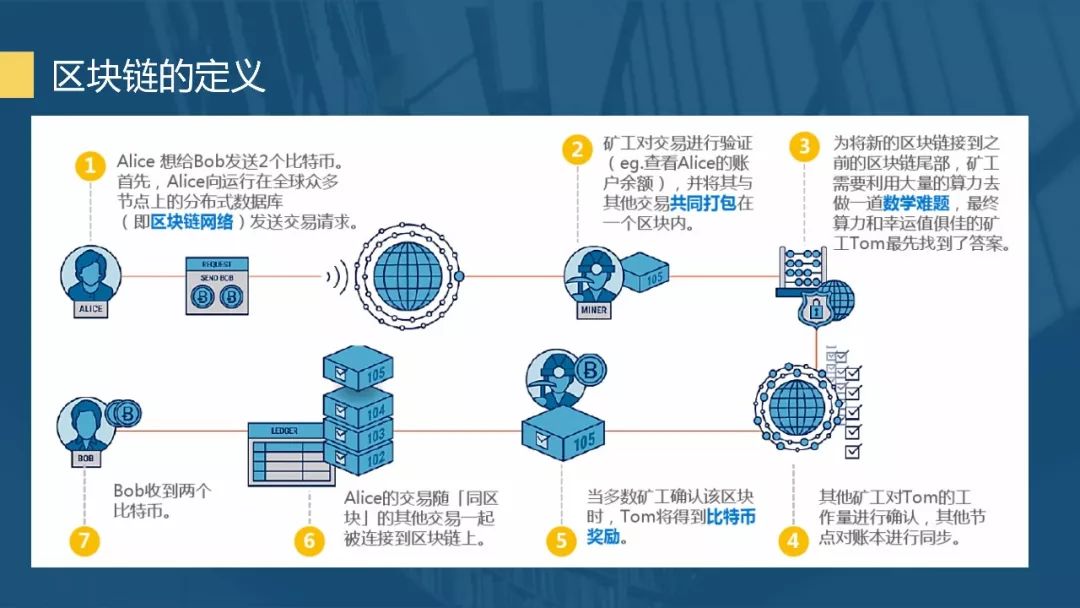
在本系列文章的开头,我们提到区块链是一个分布式数据库。但是,在上一篇文章中,我们选择性地跳过了“分布式”部分,将注意力集中在“数据库”部分。到目前为止,我们已经实现了区块链数据库的几乎所有元素。今天,我们将分析一些之前跳过的机制。在下一篇文章中,我们将开始讨论区块链的分布式特性。
该系列的上一篇文章:
基本原型
工作证明
持久性和命令行界面
交易(1)
地址
本文的代码实现变化很大,请点击这里查看所有代码变化。
奖励
在上一篇文章中,我们略过的一个小细节是挖矿奖励。现在,我们准备完善这个细节。
挖矿奖励实际上是一个coinbase交易。当一个挖掘节点开始挖掘一个新区块时,它会将交易出列并在其前面添加一个 coinbase 交易。一个 coinbase 交易只有一个输出,其中包含矿工的公钥哈希。
实现奖励很简单,更新即可:
在我们的实现中,创建交易的人同时挖掘了新区块,因此获得了奖励。
UTXO 设置
在第 3 部分:持久性和命令行界面中,我们研究了 Bitcoin Core 如何将块存储在数据库中,并了解到块存储在数据库中,而交易输出存储在数据库中。将审查的机构:

+ 32 字节的交易哈希 -> 该交易的未使用交易输出记录
+ 32 字节块哈希 -> 未使用交易输出的块哈希
在上一篇文章中,虽然我们实现了事务,但我们并没有使用来存储事务的输出。那么,让我们继续这一部分。
不存储交易。它存储的是 UTXO 集,这是一组未使用的交易输出。除此之外,它还存储“未使用交易输出的块哈希的数据库表示”,但我们现在将跳过块哈希,因为我们还没有使用块高度(但我们将在接下来在文章中继续改进)。
那么为什么我们需要 UTXO 集呢?
考虑我们之前实现的方法:
此函数查找具有未使用输出的交易。由于交易存储在块中,它会遍历区块链中的每个块,检查其中的每笔交易。截至 2017 年 9 月 18 日,比特币中已经有 485,860 个区块,整个数据库需要超过 140 Gb 的磁盘空间。这意味着如果想要验证交易比特币的工作原理,必须运行一个完整的节点。此外,验证交易将需要对许多块进行迭代。
整个问题的解决方案是拥有一个仅包含未使用输出的索引,这就是 UTXO 集所做的:它是从缓存中的所有区块链事务(迭代块,但只需执行一次)构建的,然后用它来计算余额并验证新交易。截至 2017 年 9 月,UTXO 集约为 2.7 Gb。
好的,让我们考虑一下实现 UTXO 集需要进行哪些更改。目前,查找交易的方法有以下几种:
- 查找具有未使用的输出交易的主函数。也是在这个函数中,所有的块都会被迭代。
- 创建新事务时使用此函数。如果找到具有所需数量的输出。使用。
- 查找公钥哈希的未使用输出,然后用于获取余额。使用。
- 根据其 ID 在区块链中查找交易。它会遍历所有块,直到找到为止。
如您所见,所有方法都遍历数据库中的所有块。但目前我们还没有改进所有方法,因为 UTXO 集不能存储所有交易,只能存储那些未使用的输出。因此,它不能用于。
所以,我们需要以下方法:
- 通过迭代块找到所有未使用的输出。
- 用于查找未使用的输出并将其存储在数据库中。这就是缓存的用武之地。
- 类似,但使用 UTXO 集。
- 类似,但使用 UTXO 集。
和以前一样。
那么,从现在开始,两个最常用的功能都会用到缓存!让我们开始写代码吧。
我们将使用单个数据库,但我们会将 UTXO 集存储在不同的存储桶中。所以去吧。
此方法初始化 UTXO 集。首先,如果bucket存在则移除bucket,然后从区块链中取出所有未使用的输出,最后将输出保存到bucket中。
几乎完全一样,但现在它返回一个地图。
UTXO 集现在可用于发送硬币:
或查看您的余额:
这是该方法的简单修改版本。不再需要此方法。
拥有 UTXO 集意味着我们的数据(交易)现在单独存储:实际交易存储在区块链中,未使用的输出存储在 UTXO 集中。这样比特币的工作原理,我们需要一个好的同步机制,因为我们希望 UTXO 集始终是最新的,并且存储最新交易的输出。但是我们不想在每次生成新块时都重新生成索引,因为这正是我们试图避免的频繁的区块链扫描。因此,我们需要一种机制来更新 UTXO 集:
这个方法虽然看起来有点复杂,但是做的事情却很直观。当一个新的区块被挖出时,UTXO 集应该被更新。更新意味着从新挖掘的交易中删除已使用的输出并添加未使用的输出。如果交易的输出被删除并且不再包含任何输出,那么该交易也应该被删除。很简单!
现在让我们在必要时使用 UTXO 集:
当一个新的区块链被创建时,索引将立即被重新索引。目前,这是唯一使用它的地方,即使看起来有点“杀鸡”,因为当一条链启动时,只有一个区块,其中只有一个交易,而且一直用过的。但是,我们将来可能需要一种重建索引的机制。
当一个新区块被挖出时,UTXO 集会被更新。
让我们检查它是否按预期工作:
非常好!地址获得3个奖励:
一次是挖掘创世块
一次开采块 0000001f75cb3a5033aeecbf6a8d378e15b25d026fb0a665c7721a5bb0faa21b
一个是挖矿区块000000cc51e665d53c78af5e65774a72fc7b864140a8224bf4e7709d8e0fa433
默克尔树
我想在这篇文章中讨论另一种优化机制。
如上所述,完整的比特币数据库(又名区块链)需要超过 140 Gb 的磁盘空间。由于比特币的去中心化性质,网络中的每个节点都必须是独立的、自给自足的,即每个节点都必须存储一份完整的区块链副本。随着越来越多的人使用比特币,这条规则变得越来越难以遵循:每个人都不太可能运行一个完整的节点。而且,由于节点是网络的完全参与者,因此它们具有相关的责任:节点必须验证交易和区块。另外,要与其他节点交互,下载新区块,也有一定的网络流量要求。
在中本聪的原始比特币论文中,也有解决这个问题的方法:简化支付验证 (SPV)。 SPV 是一个比特币轻节点,不需要下载整个区块链,也不需要验证区块和交易。相反,它会在区块链上查找交易(以验证付款)并需要连接到完整节点以检索必要的数据。这种机制允许多个轻钱包只运行一个全节点。
为了实现 SPV,需要有一种方法来检查一个块是否包含交易,而无需下载整个块。这就是 Merkle 树要完成的任务。
比特币使用 Merkle 树来获取交易哈希,这些哈希存储在区块头中并用于工作量证明系统。到目前为止,我们刚刚对块中的每个事务进行了哈希处理,并对其应用了 SHA-256 算法。虽然这是获得区块交易的唯一表示的好方法,但它没有利用 Merkle 树。
看看 Merkle 树:
每个区块都会有一个 Merkle 树,它以一个叶子节点(树的底部)开始,一个叶子节点是一个交易哈希(比特币使用双重 SHA256 哈希)。叶节点的数量必须是偶数,但不是每个块都包含偶数的交易。因为,如果一个区块的交易数为奇数,则复制最后一个叶子节点(即默克尔树的最后一笔交易,而不是该区块的最后一笔交易)组成偶数。
从下往上,将两个节点哈希成对连接,将合并后的哈希作为新的哈希。新的哈希成为新的树节点。重复这个过程,直到只有一个节点,即树的根节点。然后将根哈希用作整个区块交易的唯一标识符,保存在区块头中,并用于工作量证明。
Merkle 树的好处是节点无需下载整个区块即可验证交易是否包含在内。而这些只需要一个交易哈希、一个 Merkle 根哈希和一个 Merkle 路径。
最后,我们来写代码:

从结构开始。每个都包含数据和指向左右分支的指针。它实际上是连接到下一个节点的根,然后再连接到更多节点,依此类推。
让我们从创建一个新节点开始:
每个节点都包含一些数据。当节点位于叶节点时,数据从外部传入(在本例中为序列化事务)。当一个节点与其他节点关联时,它会获取其他节点的数据,连接然后哈希。
在生成新树时,首先要确定的是叶子节点必须是偶数。然后,将数据(即序列化交易的数组)转化为树的叶子,然后慢慢形成一棵树。
btcsuite/btcd 是使用数组实现的默克尔树,因为这样做可以将内存使用量减少一半。
现在,让我们修改 ,它用于在工作量证明系统中获取交易哈希:
首先,交易被序列化(使用 ),然后使用序列化交易构建 Mekle 树。树的根将是区块交易的唯一标识符。
P2PKH
我还有一件事要谈。
您会记得,在比特币中有一种脚本编程语言,用于锁定交易输出;交易输入提供解锁输出的数据。语言很简单,用这种语言写的代码其实只是一系列的数据和操作符。比如下面的例子:
5、2 和 7 是数据,是运算符。脚本代码从左到右依次执行:数据依次入栈,遇到算子时出栈,对数据应用算子,结果作为栈顶元素。脚本的栈实际上是先进后出的内存存储:栈中的第一个元素最后取出,后面的每个元素都会放在前一个元素的上面。
让我们运行上面的脚本部分:
从堆栈中取出两个元素,将两个元素相加,然后将结果放回堆栈。从堆栈中取出两个元素并比较这两个元素:如果它们相等,则将 a 放入堆栈,否则放入 a 。脚本执行的结果是栈顶元素:在我们的例子中,如果是 ,那么脚本执行成功。
现在让我们看看如何使用脚本执行比特币支付:
这个脚本被称为 Pay to Public Key Hash (P2PKH),这是比特币最常用的脚本。它所做的只是支付公钥哈希,即用某个公钥锁定一些硬币。这是比特币支付的核心:没有账户,没有转账;只是一个检查提供的签名和公钥是否正确的脚本。
这个脚本其实是分两部分存储的:

第一部分 , 存储在输入字段中。
第二部分,存储在输出中。
因此,输出定义了解锁的逻辑,输入提供了解锁输出的“钥匙”。让我们执行这个脚本:
复制栈顶元素。取出堆栈的顶部元素,使用 对其进行哈希处理,然后将结果推回堆栈。比较栈顶的两个元素,如果不相等则终止脚本。通过对交易进行哈希处理并使用 and 来验证交易的签名。最后一个操作符稍微复杂一点:它生成交易的删减副本,对其进行哈希处理(因为它是已签名的交易哈希),并使用提供的和检查签名是否正确。
拥有像这样的脚本语言实际上也可以使比特币成为一个智能合约平台:除了使用单个公钥转移资金外,该语言还支持许多其他支付方案。
总结
这就是今天的全部内容!我们已经实现了基于区块链的加密货币的几乎所有关键功能。我们已经有了区块链、地址、挖矿和交易。但是,要将所有这些机制付诸实践并使比特币成为一个全球系统,还有一个更不可或缺的环节:共识。在下一篇文章中,我们将开始“去中心化”区块链。请收听!
参考:
完整的源代码
UTXO 集
默克尔树
脚本
“Ultraprune”比特币核心提交
UTXO 集统计
智能合约和比特币
为什么每个比特币用户都应该了解“SPV 安全”
支持项目地址: